
🐍 Sneks [Part 1]: Single-Agent and Base Solution using DQN
Despite recent successes in the field of Deep Reinforcement Learning, like Alphastar or OpenAI Five there are still major problems to be tackled in a meaningful way: sample efficiency, exploration-exploitation, life-long learning and others. These problems are visible not only in complex environments but are also presents in problems specifically designed to isolate that trait, e.g. Atari’s Montezuma Revenge for the exploration-exploitation dilemma.1 2
This series of blog posts, which get inspiration from OpenAI Request for Research 2.0, will try to cover one of these problems, which is the learning instability in multi-agent systems. In these kind of environments, there are multiple agents that are learning independently: this means that the environment from each agent point of view is non-stationary, since the actions of the other player are not fixed but change over time.
This first post will deal with a preliminary analysis of the environment and a basic solution for the single agent version of the game. All the code presented in the series is available at this github repository.
What is Sneks?
The Sneks environment is a snake-like game which is built over openAI gym, but allows also for a multi-agent setting. The environment itself, beside its simplicity, has different nice features which are relevant for our goal:
- Easy to play: having a lower complexity allow to perform many experiments without having a large infrastructure.
- Environment is practically deterministic: each action corresponds to a fixed movement. The only stochasticity is the food positioning after the snake has eaten. This is useful because reduces the variability in the multi-agent setting.
- Highly configurable: we can easily tweak the number of food pieces, the number of agents, the map structure and size etc.
In this post, we will focus only on the single-agent setting, where a single snake need to eat as much food as possible without dying, which occurs when it goes into a wall or into itself. The environment returns as observation the complete board (with different possible formats), and allow 4 action, i.e. the movements in the 4 directions. The agent receives a reward of +1 if the snake eat one piece of food and -1 if it dies.
Solving snek using DQN
The DQN algorithm3 is probably the most famous DeepRL algorithm (being also the one that gave momentum to the field). There are a lot of good resources for the student that want to understand how it works (e.g. like this or this): for this reason, this post will rather be a simple application on a novel setting of the algorithm.
My code is based on this great framework, which has a good implementation of DQN using PyTorch. All the code used for this experiment can be found here. All the experiments are tracked using my favourite tracking tool, sacred, which I really recommend for its flexibility and ease of use.
Setting
The environment in these experiments is snek-rgb-16-v1, which has the following properties:
- The world is a 16x16 2D grid
- The observation is returned in RGB format
- There is a single snake and a single piece of food
- The grid is surrounded by a wall of size 1 (the effective board size is 14x14)
In this case, the environment was iteratively refined while experimenting; for example, the wall was added since it increased the performances a lot (the agent did struggle to understand where the end of the grid was without it).
A particular extension of DQN was used, namely the Dueling-DQN4, which performed better probably because the advantage function is more informative to come up with a strategy, while the value function is quite stable and increased by one only when a piece of food is eaten. The policy is represented by a very small CNN (which can be small given the low complexity of the observations), which speeds up the training process. The architecture of the network, as presented in the following table, has its full specification here.
| Layer | Type | Info |
|---|---|---|
| Input layer | Input | 16x16x3 observation |
| Layer 1 | 16 3x3 conv filters | Relu activation |
| Layer 2 | 32 3x3 conv filters | Relu activation |
| Layer 3 | 256 hidden neurons | Flattened input, Relu activation |
| Layer 4 | 2-headed 4 output each |
Differently from the standard DQN’s tricks, the policy receive just one observation (and not a stack of multiple observations in time); as we will explain later, this could be a reason for the plateau of performances we reach in this setting. We are currently working on extending this solution with the frame stack trick.
The algorithm was set with the parameters presented in the following table; for reproducibility, the sacred config used to run the training can be found here, which contains all the parameters used.
| Config | Value |
|---|---|
| Total timesteps | 10M |
| Batch size | 64 (32x2) |
| Experience Replay Size | 105 transitions |
| Optimizer | Adam, LR=1E-3 |
Results
The first results from this simple experiment are quite convincing, as we can see from the distribution of returns of the trained policy.
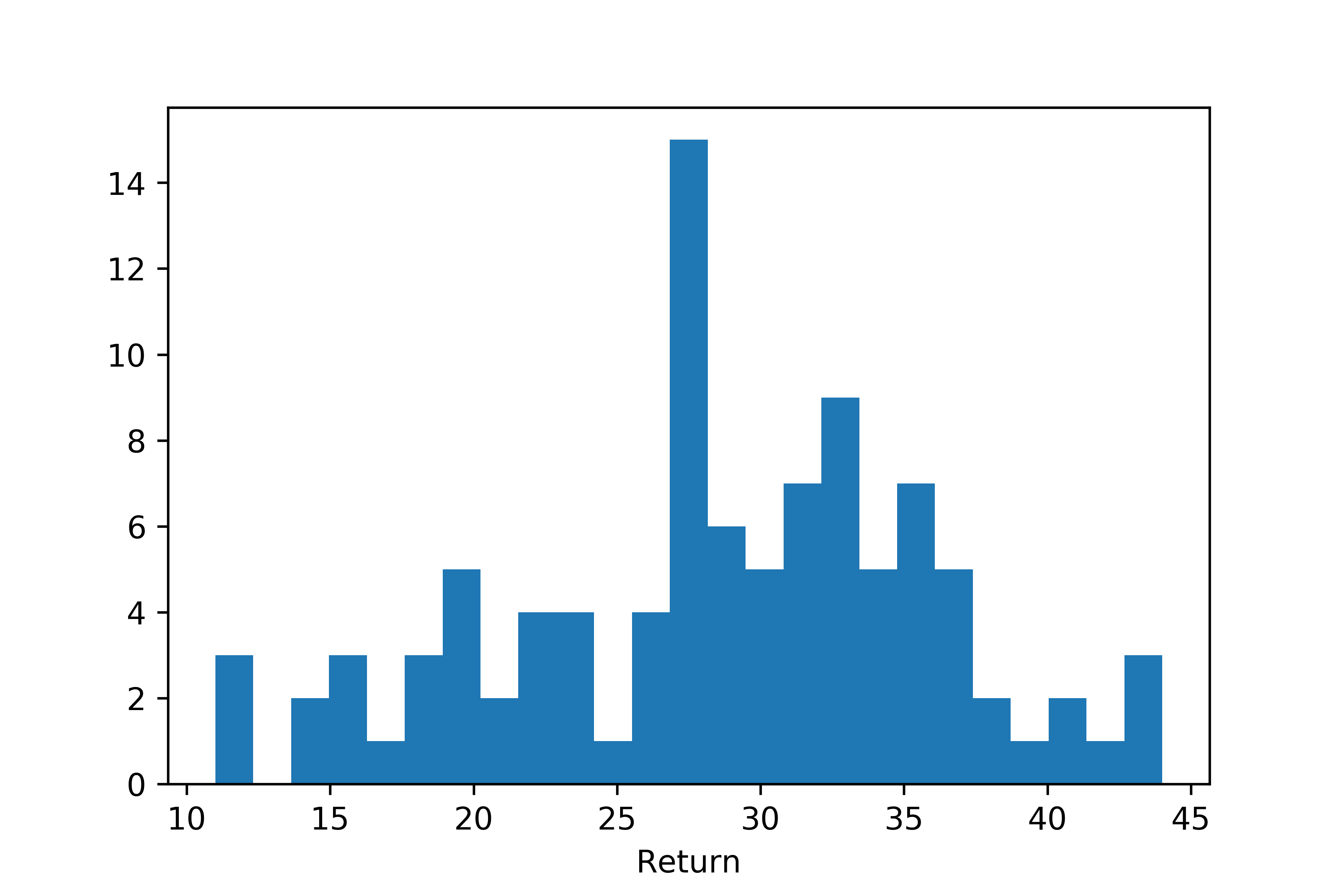 Distribution of returns.
Distribution of returns.
We also provide a render of an episode played by the trained policy, in which is visible how the agent starts to struggle when it gets bigger, probably being incapable of correctly modelling the environment behavior. We can see this plateau of performance also in the training log of the returns (which are lower than the testing score because we continue to apply an epsilon-greedy policy during training).
 Replay of the trained agent playing.
Replay of the trained agent playing.
 Returns during the training phase. At each iteration, 2 steps are taken in the environment and a batch of 64 observations are processed.
Returns during the training phase. At each iteration, 2 steps are taken in the environment and a batch of 64 observations are processed.
Work In Progress
This post will be updated soon with an analysis of the trained policy and a generalization experiment on a bigger environment. Stay tuned!
Bibliography
-
Ecoffet, Adrien, et al. “Go-Explore: a New Approach for Hard-Exploration Problems.” arXiv preprint arXiv:1901.10995 (2019). ↩
-
Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529. ↩
-
Wang, Ziyu, et al. “Dueling network architectures for deep reinforcement learning.” arXiv preprint arXiv:1511.06581 (2015). ↩